知識経営のための知識創造理論による知識資産の有効活用を本コラムで取り上げたい。社会人大学院で学んだSECIモデル(野中・紺野モデルをもとに筆者が勝手に追記修正したもの)をベースにデータマネジメントの知識創造のサイクルを俯瞰してみる。
引用文献『知識創造の方法論(野中郁次郎/紺野登(2003))のSECIモデル』より筆者が追記。
データマネジメントの基礎と理解について、DXという言葉の経緯や歴史から紐解いていく。2018年9月の経産省の「DXレポート〜ITシステム「2025年の崖」の克服とDXの本格的な展開〜」で、DXという言葉が一気に世間に広がった経緯がある。
データマネジメントの成功の秘訣
- データを理解する
- ビジネスをデータで捉える
- バリューチェーンとデータマネジメントの範囲を設定する
- データを資産として捉える
- 各組織のデータアーキテクチャを明確にする
- 個別プロジェクトから継続的な活動にする
データマネジメント施策策定のコツ
<データ活用基盤の構築イメージ>
- 連携元システム
- 各種データベース、ファイルサーバなどのDWH
- 各種業務SaaSやWEBサービス
↓
- データ活用基盤
- マスターデータ管理機能
- データ連携管理機能 ←連携元システムと連携するのはこのレイヤー
- データカタログ管理機能
↓
- データ活用(分析と解析)
- BIツール
- 各種データ利活用アプリケーション
これらのデータ活用基盤を構築した上で、データマネジメントの施策を考えていく。以下のようなステップと成果物を意識することが大事である。
データマネジメント施策の5ステップと成果物3つ
<施策>
- データ要件の整理
- データマネジメント推進要件の整理
- データマネジメント施策決定
- データマネジメント施策のKPI設定
- ビジョン設定
<成果物>
- データマネジメント施策一覧
- データアーキテクチャー
- データモデル
これらを全社的な経営課題をブレークダウンした上での施策と捉え直した上で、知識資産をデータ資産として捉え直し、知識経営のための知識創造理論をデータメソドロジーで実践していくことが大事であるというのが私見である。
知識経営に必要な知識資産とは何か?
そもそも知識とはアナログなものである。暗黙知と呼ばれる形式知化できないものを含んだ上での知識でもあり、その本質は知恵によって、具現化されたり伝承されたりしていて、マニュアルのようなものに落とし込みづらいのが特徴である。
知識はビジネスにとって本質的な資源である。
知識は様々な形態で組織の内と外に存在する。
知識はデータ社会に向かう上で必須の資源であり、情報を整えるものある。
知識はデータを活用する上でビジネスの増殖的な成長のポテンシャルを持つ。
知識は暗黙知と形式知という両面の要素を持つ複合的な存在である。
知識ベースの企業になるには?
ナレッジマネジメントを実施していくことが大事で、
①社内の技術資産を効果的に活用する
さらに、
②その技術を伝承する
プログラムを有している。
③共有と活用の仕組みを開発している
④顧客のナレッジマネジメントを支援する
また、金融的側面を与えるならば、
⑤知識資産の持つ経済的価値に関心がある
つまりは、知的資本として担保価値を把握できれば、知識も価値として共有できるのではないかと考える。
⑥現場業務に対する知識サポート
これらを知識経営の実践の行動指針の第一に掲げることが大事であり、ホワイトカラーという職業がこの世から消え去るイメージで捉えれば良いと思う。より現場に近いデータ活用が求められるという意味において、ブルーカラーとホワイトカラーという二極化した働き方の階層構造は今後は意味を為さないということを述べたい。
いずれにせよ、知識には暗黙知の属人的要素も含まれているため、ナレッジマネジメントが形式知に偏らない知識経営のマネジメント力が知識ベースの企業には常に求められるというのがその本質である。
ここまで論述していく中で、知識をマネジメントするナレッジマネジメントという方法論は、データマネジメントのプロセスとの融合を図ることでより強固な仕組みになるというのが私の方法論仮説である。
知識資産の把握をデータ自体の価値化と捉え直し、その資産を有効に活用するデータ活用こそが本来の知識経営にたどり着くと私は述べたい。
つまりは、SECIモデルですでに実現できている知識創造プロセスの方法論にこれまで議論できていなかったデータマネジメントのプロセスを融合した2層のマネジメントこそが、知識社会の到来とともに訪れたSociety5.0のいわゆるデータ社会(4.0は情報社会)への最適なアプローチだと考える。
では、実際の経営の現場では、経営と現場の乖離が起きるため、実践理論を実践することを知識創造経営では求められている。この実践理論の実践にこそ、データマネジメントが関与すべき領域なのである。
ここからは、前回のコラムで少し触れたデータリテラシーの5つの視座をベースに、具体的な方法論を論じてみる。上記で述べてきた知識創造経営のためにどのようにデータマネジメントを実践するかといえば、まずは、
「1つの研究サイクル」
を意識して、なんからの目的に応じた課題や事案などに対する対処理論を考える。つまりは研究者が研究対象に対して、先行研究を行い、既存の理論やメタ理論を基に新たな新規の仮説を立てていく概念化によって考える。
そこで重要なのは、1つの研究サイクルで実現する大きなグランドセオリー(誇大理論)を仮設検証によって、求めがちであるが、それは研究者が何年もかけて追い求める理想の形であるが、ビジネスの現場での理論化への実践理論の実践とは、そこも当然結果が出るのであればそれは御の字だが、現実はそうはいかないし、全ての仮説検証が完了する頃には、そのビジネスへの時間軸やアプローチはおそらく失敗に終わっているだろう。
そこで重要になってくるのが、
「2つのデータ解釈」
である。研究サイクルを傍観すると、当然のこととして、仮説検証のためのデータ分析後の解釈を通常のデータ解釈と解釈するのが当然であるが、私がここで言いたいのは、もう一つの解釈である、データ分析前の解釈のことである。そんな解釈は分析前なので、意味がないと思われるかもしれないが、私が提唱しているデータリテラシーのためのデータメソドロジーとして、
「3つの研究法のトライアンギュレーション」
という方法論がある。別にこれらはこれまで研究者が研究をするにあたって、ずっと継続して実践されてきた研究法である。そのため何か私が大発見をしたと大騒ぎするようなことではないが、ここで私が伝えたいのは、知識には暗黙知が内在するということを述べたと思うが、その暗黙知を以下に意味付けして、分類して形式知化しながら、他者への共有・標準化を図っていくかをビジネスの現場で実践する場合には、このデータメソドロジーを、グランドセオリーのための仮説検証の大枠のデータ分析を行う前段で、繰り返していく作業が大事だと述べたい。特に、数理演繹法と統計帰納法は、定量的なデータを分析する際には、効果的な方法論であるため、データ同化といったメソドロジー含めて、当然すでに実践されている。ここでは、一般的に聞きなれない研究法である、
「意味解釈法」によるデータ分析前の「データ解釈」
の実践を行えばという提言である。また、混合研究法で言うところの定性的な研究法に用いられている研究法は以下のように列挙できる。
意味解釈法
- カテゴリー分析
- テキスト分析
- パーソナル・ナラティブ分析
- グラウンデッド・セオリー
- 内容分析
- 意味論的分析
- シンボリック相互作用論
- テーマ分析
- コンテキスト分析
- ディスコース分析
等々があるが、因果推論と事前事後の確率分析であるベイズ統計の手法によるベイジアンネットワークとグラウンデッド・セオリーのアプローチを混ぜた研究法を方法論仮説として、私見で持っている。
ここで重要になってくるのが、意味付けした事象や現象などに対しての
「4つの尺度基準」
を理解しておくことである。特に、定量的な尺度としての間隔尺度と比率尺度と相対する定性的な尺度としての名義尺度と順位尺度をきちんと活用含めて理解しているかが鍵となる。
つまりは、尺度基準で把握されうる意味を付与した定性的な尺度基準の
「名義尺度」
こそが、暗黙知を分類して、意味を付与し、知識創造の源泉になると言えるのである。(これをみんな理解してないので、データ分析の解釈が意味をなさない世界観で理論構築が出来上がってしまうのである)
名義尺度で把握され、意味を付与された事象や現象を、どう定量化していくかを学ぶためには、第5代統数研所長であった林知己夫先生の著書「質を測る」を読破することをお勧めする。そこでは、質的な尺度を以下にフォーミュレーションを図って量的に把握していくかということが書かれている。先に結論から言えば、名義尺度は通常、0と1で表現されるようなデータになるが通常であるが、ナレッジマネジメントにおける知識創造のポイントとして、この0と1ではない現場で実践されうるデータ解釈による実践こそが、0と1の定性的な尺度基準である名義尺度の表現の中に存在する多次元的な量化の変数の存在の可能性を探ることができる。
ここまで述べてきたところで、前回も述べた最後のデータリテラシーである
「5つのビッグデータ再定義」
の話で締めたいと思うが、今DXブームによって持て囃されているデータ活用の実践の前に、データの種別化をきちんと理解していくことも大事であると述べたい。それはビッグデータブームの時に定義されていたデータの種別化に対して、4つの新たなデータ(4D)種別を意識していくことで、ナレッジマネジメントとデータマネジメントが融合できる必須条件となり得るわけである。
以上、ここまではナレッジマネジメントとデータマネジメントの融合を図る前段の準備についての知見を述べてきた。
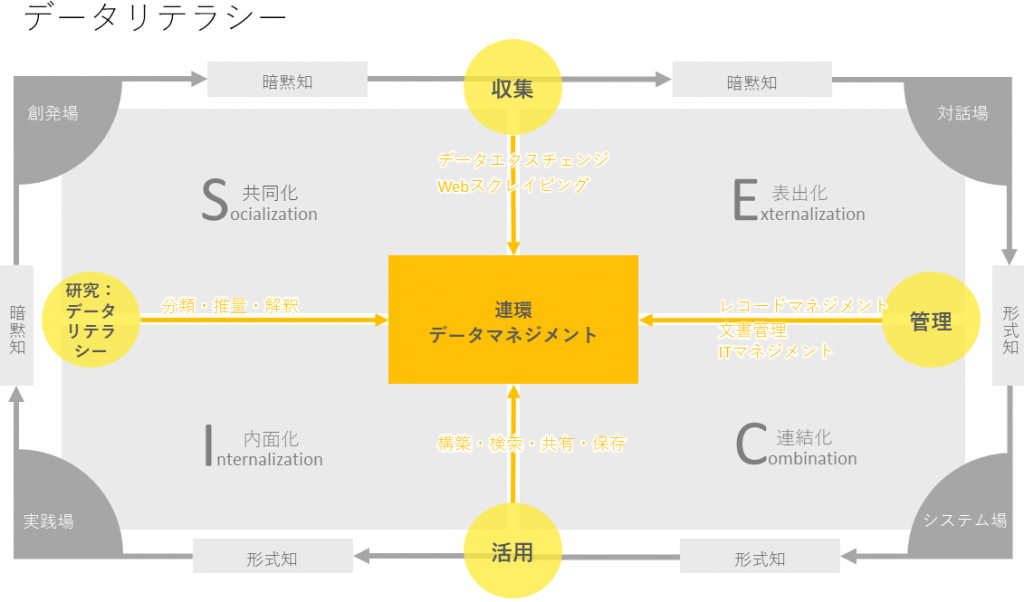
ここからは、ナレッジマネジメントとデータマネジメントの融合が具体的に以下の連環データをマネジメントすることで進められるということを述べたい。
引用文献『知識創造の方法論(野中郁次郎/紺野登(2003))のSECIモデル』より筆者が追記。
基本的に、SECIモデルのSocialization(共同化)における
「データの収集」
段階において、AI-OCRやウェブスクレイピングや一定のフォーマットによるデータのアップロードなどによって、データを集めるフェーズがあるが、その段階においては、暗黙的なナレッジを形式知化していく段階にあるため、人と組織の間における何らかの知識をデータとセットで溜め込んでいく必要がある。この時に重要になるのは、以下に暗黙的な知識の取りこぼしを形式知化したデータから取りこぼさずに、組織人同士で認識し合うことが大事である。
カタログ管理やメタデータ管理によって、そこを補いつつも暗黙知そのものは把握できないため、構造的な存在を何らかの形で表現しておくことが大事である。
次に、SECIモデルのExternalization(表出化)における
「データの管理」
段階においては、データ管理、情報(IT)管理、ナレッジ管理を統合的に管理する組織的なルールの構築と、同時に文書管理に使われているレコードマネジメントの要素を横断的な管理の手法として用いることが鍵となる。
そこでは、当然データ管理されたデジタル文書は当然のこと、
契約書
レポート
監査
証明書
といったビジネスにおける重要な紙の文書やオフライン形式の記録や電子メールや何らかの画像や動画などの非構造化データの記録管理を行う必要がある。
ここで重要なのは、既存のフォーマット化されたデータは、一見形式的で、それ以上の価値を生み出すものではないように見えるが、その各資料のレコードを超えて、連環データは繋がりのあるマネジメント機構を持ったデータ活用の手法を用いることにより、文字が違えど重要な統計的な連関のある2つの属性間に相互作用のある関係性をみていくことで、連関を持った関係性を管理していくことができる。
そして、SECIモデルのCombination(連結化)における
「データの活用」
段階においては、ナレッジマネジメントにおいて、形式知化されたマニュアルの作成から、共有を図っていくことで、レコードとして記録され、全て統合的に管理されたデータを検索、閲覧、共有できるようにしておくことが大事である。
ここまではIT業界の中だけでシステムとして閉じられる領域ではあるので、各企業が知識創造経営を行いたい場合に、この時点で、大部分の暗黙知と呼ばれる知識は相当な部分が削ぎ落とされている前提で、データの活用を考える必要があることを組織として理解しておく必要がある。
この次の段階であるSECIモデルのInternalization(内部化)こそが
「データの研究」
という段階を踏まないと、ナレッジマネジメントが成功せず、ITインフラの形式知化された情報をもとに経営の意思決定やマーケティング戦略の立案や製品・サービスの品質に寄与できるデータ活用ができない。この部分が欠けていたために日本の失われた20〜30年が継続してしまったと言っても過言ではないだろう。(これはあくまでも私見なので、立証はされていないが)
ここまでで述べている私が行ってきた研究法の研究によるデータリテラシーのあり方と研究者が行っていた研究対象ではなく、研究メソッドを科学の領域から切り離して、このデータ活用のためにメソドロジーとして組み込むことにより、ようやくナレッジマネジメントがデータマネジメントと融合ができるのである。
では、具体的にどうすれば良いかは、第2回のコラムを読んでもらって、さらにそこに書かれている3つの研究法のトライアンギュレーションを実践することが大事であると述べるに留めておく。
次回以降でもコラムで、具体的な方法論にも触れていくが、そろそろ著書によってまとめていくことも考えていく次第である。