エッセンスは以下の5つ。
キーワードとしては、
「1つの研究サイクル」
「2つのデータ解釈」
「3つの研究法のトライアンギュレーション」
「4つの尺度基準」
「5つのビッグデータ再定義」
データリテラシーの本来の意味は?
以下の2つの意義から導き出したデータリテラシーの必要性を説く。
研究法の研究をする意義
IT業界に身を置いて四半世紀が経ち、データ処理系のインフラ基盤やデータ分析のシステム作成の案件をこなす傍で、近年ビッグデータという一つの潮流ができあがり、市場で盛り上がりを見せているなか、自身の経験則として、顧客側も提案するシステム側も体感的にデータから知見を得るという方法について理解が乏しい為に、ガーベージインガーベージアウトなシステム提案と導入が発生していることが多いと感じている。
そんな中で、データから何を得て、何のためにそれを使うのかという方法論としての研究法が周知されるべきデータ社会の到来によって、データリテラシーの基礎となる研究法自体を理解することに意義があると感じていて、長年の業務の中から得た自らの経験が、研究法を研究することによって、その積年のもやもやした課題を解決する糸口になると考えたために、その意義を本コラムで述べたいと思う。
先行研究としての混合研究の研究をする意義
「質を測る」で述べられた林知己夫氏の数量化理論の元となる考え方をベースに、カテゴリーデータとよばれる統計上の変数を社会学的アプローチであるグラウンデッドセオリーで、理論ができあがるまでにサンプリングデータを収集し続ける理論的サンプリング技法と理論が出来上がるまでコーディングしておくオープンコーディング後の体系化を構築していくためにも、西里氏の質的データの分析法を見定めつつ、分類と配列メソッドとの兼ね合いも含めて研究法を参考に定性と定量の研究法を戦略的にまとめていくこととする。
上記の2つの意義は、方法論としての仮説を研究の土台として考えるにあたって、研究法自体を研究するという大胆な発想と自然科学の領域よりも、より人文科学や社会科学の中で適用が進んでいる混合研究の研究法を加味した上で、現実的なビジネスの世界のデータ社会における、より実践的な方法論適用概念として、1つの私見を述べさせてもらう。
DX時代のスキルセットを考えると、AIにおいてはデータサイエンティストのスキルセットであった①データエンジニアリング(プログラミング能力)や②データサイエンス(統計学や機械学習モデル構築)の力が重要視されていたが、③ビジネスに対して、どのような目的や目標を持ち、経営戦略やマーケティング、製品やサービスの品質向上のためのビジネス自体の解釈力が重要になってきていると思う。文字通りThink in Data(データで考える力)スキルが大事であると。
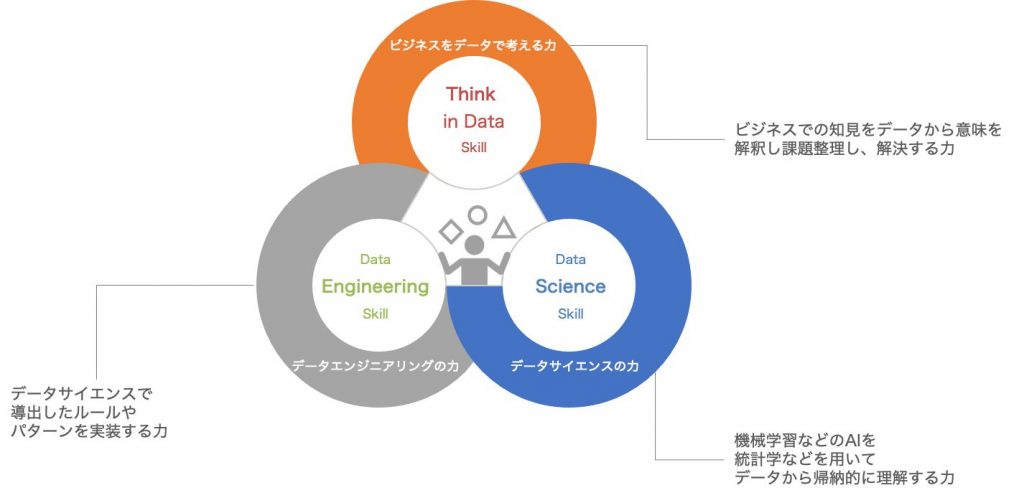
では、データで考えるためのリテラシーとは、何か?
昔でいうところの江戸時代に寺小屋で習った「読み書きそろばん」といった部分を深掘りすると、データを読み書きして、AI(そろばん)をはじくというようなシステム的な話に行きがちだが、私が考えるスキルとは、ITという情報技術のスキルではなく、そもそも人間が持っている思考や判断に係る分析能力のための思考法、つまりは研究者が研究をするにあたって使っている研究法に着眼して、そのスキルセットを伸ばす事が大事だと考えているわけである。
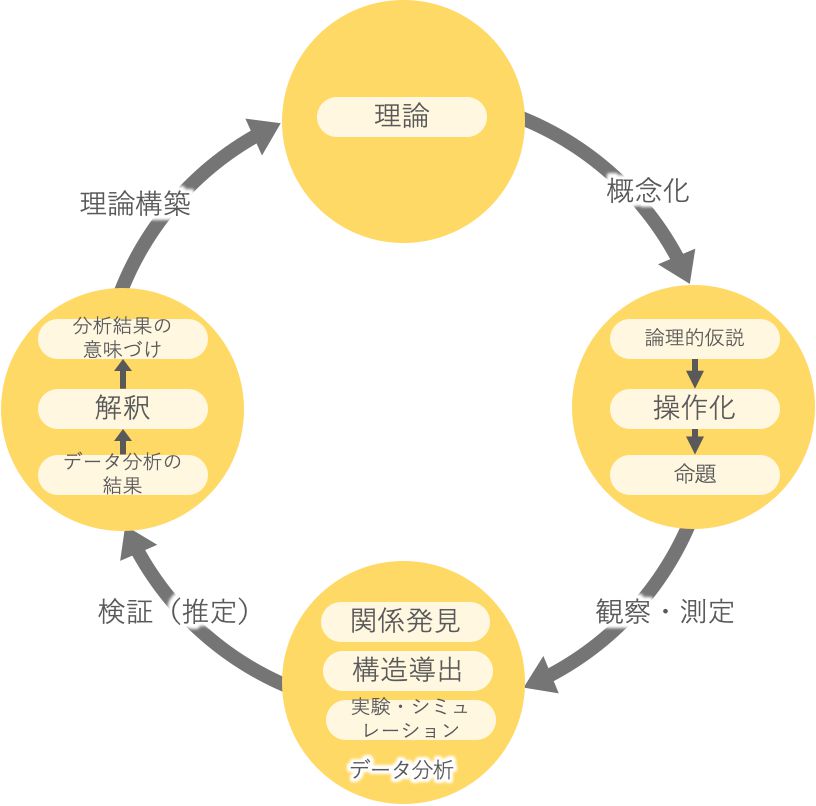
研究を進めるにあたって、理論を作ることが研究者の目的である訳だが、その理論構築のためには、先行研究や既存の理論をまずは、調べながら新たな論理的な仮説といった概念化の作業を行なっていく、つまりは研究者が理論を構築していくかのように1つのサイクルを回していく一連の流れがある。
これが、
「1つの研究サイクル」
を意識するということである。
図示されているように、概念化を行い、仮説を作る。その後、観察や測定を行って、何らかの関係性を見つけ出し、現象や事象への構造を導出して、データ分析を行っていく。データ分析による検証を行い、最終的にその結論における解釈を行って、一般的にデータ分析を行ってから解釈を実施して、結論を導き、一つの理論構築を行うわけだが、ここでのデータリテラシーの2つ目の視座として、
「2つのデータ解釈」
がある。
この2つのデータ解釈の存在を認知することによって、1つの研究サイクルにおけるデータ解釈の位置付けが明確になることで、データリテラシーを高めることができると言える。
それを説明するためには、3つ目の視座である
「3つの研究法によるトライアンギュレーション」
を理解する必要がある。
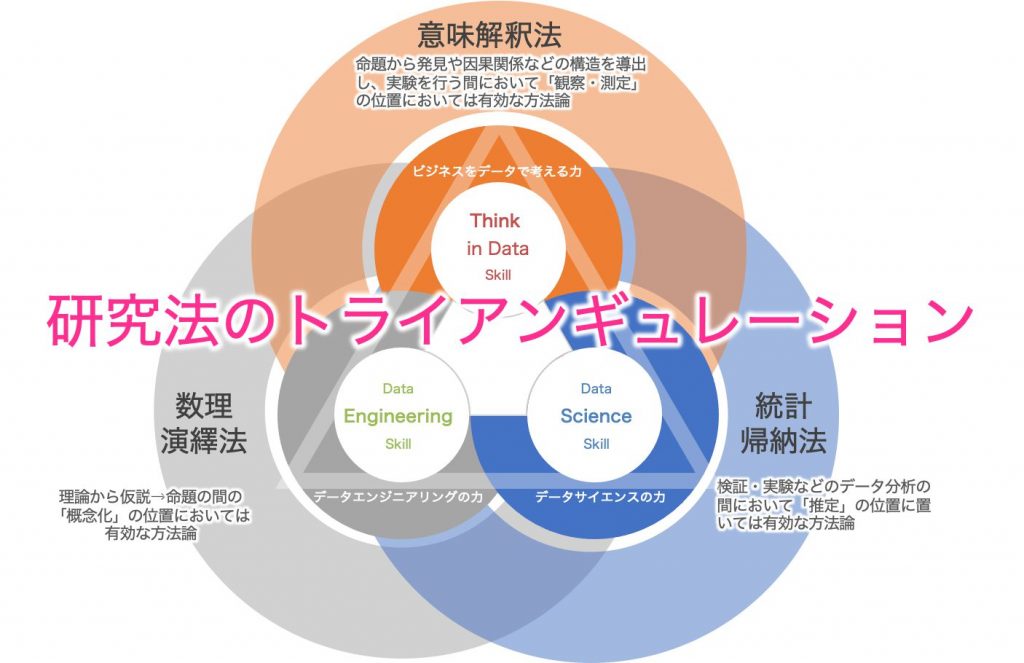
これを研究サイクルに当てはめてみると、ある種の演繹的な既存理論やメタ理論からの仮説や命題を求めていく過程で、何かしらの研究の方向性を見定めるのと同様に、ビジネスにおける関係性や構造の把握も、当たり前のことではあるが、観察や測定などによって、データを分析する前段でその仮説検証のための意味解釈を実施していくことが多い。そのため、これまでの一般的なイメージにおけるデータ分析後の仮説検証後の解釈性の話とは区別して、このもう一つの意味解釈法を学び取る必要があると考える。
ここで、2つのデータ解釈のうち、データ分析後の意味解釈、つまりは仮説検証後の研究法の方法論については、いわゆる統計的な分析などに基づくメソッドがすでに多くの書籍にて説明なされているため、ここではその内容は省く事とする。
また、データ分析前の意味解釈法による方法論については、本コラムにおいては、1つの方法論仮説を提示するに留めるが、私自身が実際の仕事の現場で使っている方法論は、グランドセオリーではなく、より領域密着理論であるグラウンデッドセオリーを見つけ出すためのGTAという方法論である。
これは、簡単に単純化できる話ではないが、混合研究法の中で用いられる方法論でもあるが、人間の主観性や社会現象といった人文科学や社会科学の領域において、自然科学の物理法則のように、単純に科学的な再現性を法則として、シンプルに見つけ出せるようなグランドセオリーとは異なり、個々別の事象や現象における説明力の高い質的な研究の中で培われた方法論を適用概念として用いようとしている。
ここで大事なのは、アカデミアの世界とは異なる現実のビジネス社会におけるデータリテラシーの方法論として、より実践的な方法論をデータリテラシーとして適用しようとしている点にある。
つまり、数理演繹的な研究法と統計帰納的な研究法はこれまでデータ同化といった地球シミュレータなど、さらにはそれをマーケティング分野に応用するなどの研究法適用の理論はあったかと思うが、より人文科学的、社会科学的な密着領域の分野での理論構築として、より現実に即した事象、現象の把握のための方法論はなかなか提示されて来なかった点を補完するために、意味解釈法という一見科学的に思えないような3つ目の科学的方法論を上手く組み合わせる、つまりトライアンギュレーションすることで、より質的な意味空間における精度や粒度や次元に対して、真理に近づけるような方法論を適用概念として用いることを提言したいと考えている。
ここまでで、1つの研究サイクルにおける2つのデータ解釈を3つの研究法のトライアンギュレーションで捉えることで、実はAIのモデル構築や現象そのものをデジタルツインで表現した後のデータ分析のための仮説構築が組み立てられるようになってくることが理解できると思う。
ここで重要になってくるのが、世の中には、
「4つの尺度基準」
があることを知ることである。
尺度を与えることで何が得られるかというと、4つの尺度のうち、質的変数は
名義尺度と順序尺度
があり、量的変数としては、
間隔尺度と比率尺度
があることをまず知って欲しい。
この尺度基準があることは研究者は誰もが知っているが、一般的な人がこれをきちんと把握していることはレアケースであり、これは学歴や偏差値教育とは全く別で、この尺度を理解して、データ分析を行ったり、データの解釈を行うことができていないせいで、日本はデータリテラシーにおける後進国になってしまっているといっても過言ではないであろう。
では、何をすれば良いのか?と思われると思うが、これは
「5つのビッグデータの再定義」
の話と絡めることで説明ができる。
これは長年ビッグデータという言葉が生まれてから、少なくとも私が出会ってきたビジネスマンや企業人の方々がビッグデータを誤解し、理解していない点と符号する。
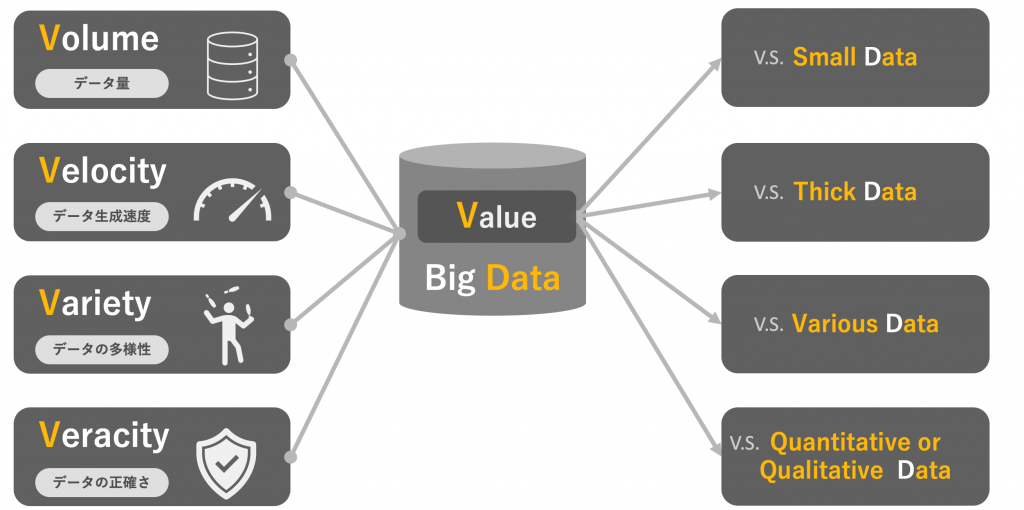
巨大なデータや様々なデータがあることが知見を何らか得られると勘違いしてしまっているビジネス界とそれを是正できないアカデミアの中庸を取るためのバランスの話になる。つまり、先に結論を述べると先の尺度基準を用いたデータの取り扱いができておらず、さらに、データ分析前のデータ解釈による仮説構築ができていない。これを認識し、是正するだけでも国内のDX時代の生産性は向上することは間違いない。
ただし、具体的にどのように尺度基準を用いて、ビッグデータを取り扱うのかという一番重要な方法論こそがデータリテラシーの内容になる訳だが、本コラムにおいては、データリテラシーの5つの視座を提示するに留める。
次回以降のコラムにおいては、このデータリテラシーを使って、何をすべきかという目的や具体的な方法論を提示したいと思う。
キーワードとしては、
ナレッジマネジメントとデータマネジメントの融合
がそのためのヒントとなり得る。