意味解釈法という研究法の要旨と混合研究法の組み合わせ
研究の本質は分類して、推論して、解釈することで、理論を構築する。
つまり、理論を構築することが、ビジネスにおける法則性などを予測するモデル作りや人工知能などへの応用へと可能性を広げられるということを明言したい。
通常、先行研究がない研究は、最初の分類時点で、新しい研究対象の現象や事象を、その事象が起きている現場のデータによる解釈が必要で、トライアンギュレーションを意識して臨まないと、定式化されていない研究領域においては研究が前に進まないループに陥る。これまでのコラムで書いた3つの研究法のトライアンギュレーションは、意味解釈法、数理演繹法、統計帰納法であるが、意味を解釈するという一義的な目的をベースにビジネスへの応用領域を定めることが大事だと述べてきた。これがビジネスの場合、新規事業を考える際には、いわゆる「先行」した研究のない事象や現象に意味づけを行い、分類から推論に至る研究プロセスの工程を経て、理論構築のための実証主義的な分析後の解釈にまで至らないと研究による理論が構築できないわけである。つまりは応用研究でもあるビジネスへの適用概念を確立することなどはもっと難しい話になってしまう。
また、意味解釈法における重要な要諦は、社会的な人間も含めた相互作用及びその研究対象そのものがプロセスをも包含するような研究メソッドを提供することであり、研究する人間と研究対象をも巻き込んだ社会学的な意味合いを含む研究メソッドを使うことで、人工知能やビジネスインテリジェンスへの適用をももたらすことができると筆者は確信している。
ただし、意味解釈法そのものだけでは、これまでの科学としての危うさは常に指摘されてきた。当然、科学的事象の再現性への担保や研究者の主観性による独我論に陥りやすく、主観的客観性(客観的なものを主観的に述べてしまう非科学的な解釈)のリスクが内包されてきた。そこで、より領域を絞った領域密着型の理論構築の方法論として、社会学的な意味解釈法の研究メソッドとして有名なGTA(Grounded Theory Approach)がある。
方法論として1960年代に発明されたものであるが、その方法論自体も改良がなされ、修正版GTAと呼ばれるM-GTAという方法論が木下康仁教授によって提言されてきた。一言で言えば、理論構築の過程において、切片化をやめて、分類のためのデータ整理を行うのではなく、真に概念や理論構築に特化した方法論として整理されている。
いずれにせよ、社会学的なアプローチによる意味解釈法を前提とした理論構築の方法は今から半世紀も前に発明されているわけである。これをビジネスに活かすことを提言してきた人は少ないのである。
それはなぜか?
冒頭にも書いたように、実証主義の研究パラダイムに則ったフォーミュレーションに従った研究が盛んに行われたため、実証主義的な仮説検証プロセスの研究前のデータ解釈による解釈主義的な研究法自体の存在を非科学的と軽視してきた経緯があると推察される。
そこで、これまでコラムで述べきた研究法による方法論の組み合わせが重要になる。いわゆる研究法のトライアンギュレーションがここで重要になると重ね重ね申し上げる。本コラムではそれぞれの理論や具体的な用語についてはの解説は行わないが、GTAで理論構築した事象や現象の構造や動的なプロセスに対する再現性などの科学的なアプローチが重要で、解釈主義と実証主義の狭間を埋めるための混合研究が大事で、つまりは数理演繹と帰納統計のメソドロジーをここで活用して行くのである。GTAでコーディングした分類後の事象や現象に対する推論について考察しておかないといけないが、事象や現象の再現性確立のための推論には、事前と事後の確信度の分配ロジックを明確に定義出来るベイズ推論を用いて、推論するが、そもそも推論という言葉には研究法3つのアブダクション推論という概念もある。つまり、常にトライアンギュレーションで捉えて、研究領域と研究手法を多面的に見ていかないと正しい解釈はできないというロジックをその理由とする。GTAの領域密着理論の狭小性と階層化された事前・事後の確率論がマッチするのではないかと言う方法論仮説に基づくものである。
意味解釈法から発芽した理論の可能性
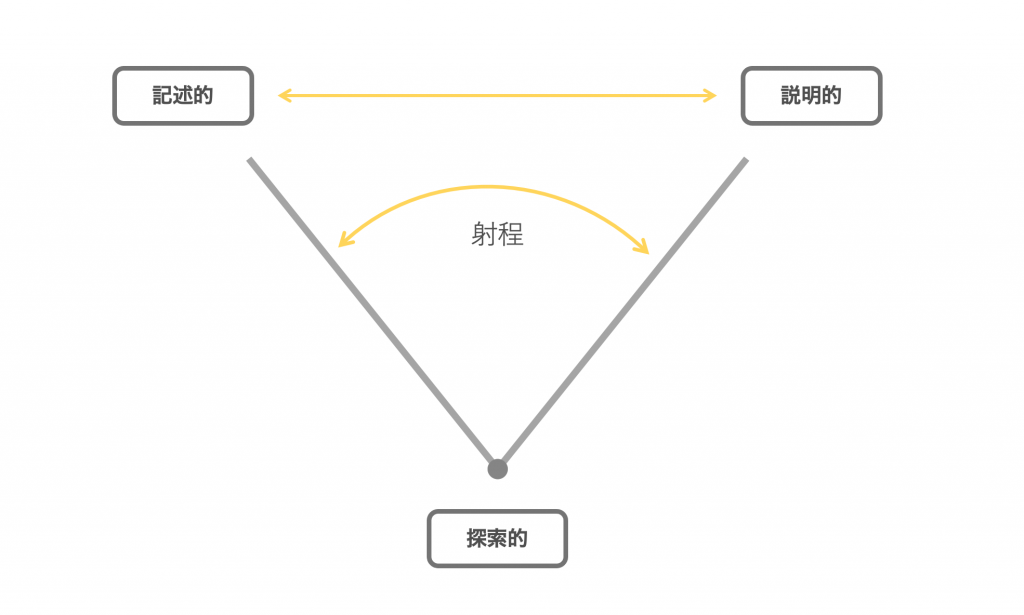
研究法の射程としては、対立軸として、
記述的な理論(Descriptive)
↓↑
説明的な理論(Explanatory)
が研究メソドロジーの概念として存在する。
この射程を常に「探索的に(Exploratory)」に常にその研究領域を文字通り探索することで、理論構築のためのデータ解釈プロセスを継続させることが重要である。つまり、意味解釈法を使って、解釈主義と実証主義の狭間の理論を構築ができるということである。
また、ここで先に述べておくと、記述的な理論というのは、科学的ではないという考えが一般的にあるようだが、実際のところ研究法の研究によるビジネス領域での応用研究においては、Descriptiveなものに近づけば近づくほどビジネスの成功への階段を登るための理論としての蓋然性は高まる。
つまりは、GTAによって発芽した事象や現象の時系列も含めた変化のプロセスを法則性を持って仮説検証するところまでの理論化そのものを統合的に体系化して理論構築できるということが大事である。そこがまさにトライアンギュレーションと言っている3つの研究法の統合的な活用方法の道理である。
ここから先は、私の研究の中でも最も重要なベイズ統計やベイジアンネットワークの方法論との組み合わせ理論であるため、私自身が科学的な確証を理論的に方法論仮説として立証していないが、ベイジアンネットワークを考えたジューディア・パール著の「因果推論の科学(2022)」を読めば、因果推論のロジックとなる、関連付け、介入、反事実の方法論が記載されており、私がGTAで取り組もうとしていた内容がそこに含まれていることからも、逆説的に統計的な因果推論の限界についての新たな方向性を示した書物であるが故に、私が立証せずとも一旦は方法論的仮説検証をせずに言い切った形でこのコラムを書き進めたい。
ベイジアンネットワークによって、事象や現象の因果関係を図式化していくことで、意味解釈法によるビジネスへの適用概念の幅や有効性を述べることができる。つまりは確率による蓋然性を予測する人工知能の機械学習モデルを設計するなどの応用の可能性が期待できると明言したい。
これまでのGTAにベイジアンネットワークを混合研究法に基づく応用理論によって、結べつけていくことで、GTAの持つ本来のメソッドであった統計的サンプリングとは異なる、理論的サンプリング手法の方法論を数学的に考えることも検討することができるようになってくる。そして、まだ意味解釈法をベースとして、3つの研究法のトライアンギュレーションというデータメソドロジーを用いてその方法論と「意識的に」使いこなすビジネスサイドの提言は少ないと私は考えており、この辺をアカデミアとも協調して、体系化を今後図っていきたいとは思っており、一旦その方法論仮説の立証は据え置いて、私見を以下に述べさせてもらう。
GTAの理論的サンプリングと数学/統計学との融合
意味解釈法であるGTAをデータ中心に捉えて、数理演繹的な方法論として数学を、帰納統計的な方法論としての統計学を組み合わせて、統計的サンプリングとは異なる、データ分析前のデータ解釈による探索的なデータメソドロジーをここに記述する。
GTAは、社会科学や経営学などの研究分野で使用される質的研究手法の一つである。この手法は、データ駆動型のアプローチであり、新たな理論や概念を組み立てるために、具体的なデータから抽出されたパターンやカテゴリを分析をおこっていくものである。
GTAの特徴的な要素は次のとおり。
- 理論駆動型ではなくデータ駆動型:
GTAは、あらかじめ存在する理論や仮説に基づいて研究を行うのではなく、収集したデータから新たな理論や概念を抽出することを重視する。 - コード化とカテゴリ形成:
GTAでは、収集したデータ(インタビューテキスト、観察記録など)を詳細にコード化し、パターンやカテゴリを特定する。これにより、データの解釈や意味付けが進められる。 - 経験的な一般化:
GTAは、データから得られたパターンやカテゴリを通じて、より広範な理論的説明を構築する。これにより、具体的な状況や現象からより一般的な原則や概念が導き出される。 - 反復的なプロセス:
GTAは、反復的なプロセスを特徴としている。データの収集、分析、理論の構築といったステップを繰り返しながら、理論が発展し洗練される。
GTAは、新たな理論の構築や既存の理論の補完・修正を目指す研究者によって広く使用されている。データ駆動型のアプローチとして、研究対象の実態に基づいた深い理解を提供することが特徴である。
理論的サンプリング(Theoretical Sampling)は、質的研究において、研究対象の理論や概念を発展させるためにデータ収集を進める際に使用される手法である。一般的にはグラウンデッド・セオリー法(Grounded Theory Methodology)と関連して使用される。
数学的な応用として、理論的サンプリングは確率論や統計学におけるサンプリング理論とは異なる。ただし、数学的なアプローチとして、理論的サンプリングに関連付けることができるいくつかの方法論がある。以下にいくつかの例を挙げられる。(これらの記載はあくまでも私見に基づく根拠のない妄言であることは現時点では言い添えておく)
- パラメトリックブートストラップ(Parametric Bootstrap):
パラメトリックブートストラップは、確率分布のパラメータを推定するための統計的手法である。理論的サンプリングでは、新たなデータを収集するために既存の理論や概念を使用することが求められる。パラメトリックブートストラップは、既存のデータから得られたパラメータを基に、新たなデータのサンプルを生成する方法がある。 - ランダムウォーク(Random Walk):
ランダムウォークは、確率過程の一種であり、ランダムな移動を繰り返すものである。理論的サンプリングにおいては、理論や概念の探求を目的として、既存のデータや理論からランダムに次のデータや概念を選択することがある。この場合、ランダムウォークのアイデアを応用して、次のステップをランダムに決定することが考えられる。 - モンテカルロシミュレーション(Monte Carlo Simulation):
モンテカルロシミュレーションは、ランダムな数値の生成を通じて、複雑な問題を解析するための手法である。理論的サンプリングでは、既存の理論や概念から新たなデータを生成し、そのデータを基に理論の構築や検証を行うことがある。モンテカルロシミュレーションを使用すると、既存のデータから新たなデータを生成し、理論の推論ができる。 - 数値最適化(Numerical Optimization):
数値最適化は、数学的な関数の最大値や最小値を求める手法である。理論的サンプリングにおいては、データ収集のプロセスを最適化するために数値最適化手法を使用することが考えられる。これにより、理論的な洞察をより効率的に得ることができる。
意味解釈法をベースとした方法論を取ることで、統計的サンプリングに加えて、GTAの理論的サンプリングに応用が可能となる。ただし、理論的サンプリングは質的研究の手法であり、定量的な数学的手法とは異なる特徴を持つ。そのため、数学的手法を理論的サンプリングに適用する場合には、今後、適用の方法論としての仮説検証による立証が大事となって行くと考えている。
つまりは、冒頭で申し上げた研究の本質は分類して、推論して、解釈することで、理論を構築により、ビジネスにおける法則性などを予測するモデル作りや人工知能などへの応用へと可能性を広げられるということを改めて明言したい。
先行研究としての意味解釈法の研究法は、3つの研究法のトライアンギュレーションを実施する際に最も優先的、序列上位の研究手法であり、まずその組み合わせにおいて、一番上位にそれを如何に組み合わせて、実践することが大事である。研究対象に合わせて実証研究的に、仮説検証を実践することも大事だが、私が常々語っている意味解釈法をデータ中心に捉えて、何かしらの事象や現象の法則性を発見や考察や体系化していくという行為は文字通り社会学的な行為の意味論として非常に重要な結果をもたらすと考えている。
探索的に研究対象を探しているそのプロセスにおいて、それは研究者が研究対象に対して、実証主義的な研究の仮説検証のデータ分析をする前段の意味解釈法がビジネスでデータで考えるには重要であると説いている。
それはある意味においては、記述的な理論が即座に構築できることも意味しており、わざわざ科学的な実証主義によるプロセスを経て、理論的飽和を時間かけて結論を導出する必要のないことも自明である。