中林:私がデータサイエンティストを目指す際に、手始めに大学で教えられているような統計・数理モデルを勉強してみました。
そこで、統計との違いに気がついたことがあります。既存の統計や数理モデルだけでは今のビッグデータ時代にフィットしないケースがあります。
—— 古いということですか?
中林:いえ、基本となる数理モデルは普遍で重要です。
ただ、モデルを自ら作り、組み合わせるアプローチが必要ですし、ビジネスでは教科書どおりのケースは少ないのです。
例えば統計学はひとつの答えを出そうとしますが、ビッグデータビジネスにおいて、ECサイト の会員分析では10万人いれば10万のアプローチがあってもいいはずです。同様にセンサーデータのログ分析では異常が出るパターンは千差万別で、異常系の アルゴリズムを作るのは難しいのです。
—— おっしゃるとおりです。教科書としては誰でも納得する答えを使わないといけないですからね。
「データで考える力」イニシアティブで実施しているトレーニングでは、個々の数理モ デルに入る前に全体を俯瞰して考えるための「Stat Quadrant for Big Data」というマトリックス図を利用することを推奨しています。「比較・構成・変化」という分析軸と「共通性・関係性・集合化・法則性」という軸で分解 し、それぞれのフェーズで必要なアプローチを紹介しています。
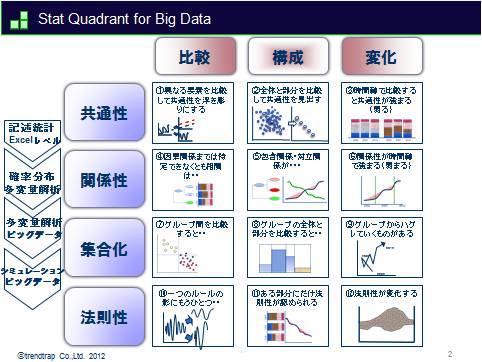
中林:はい、あのように俯瞰して考える力は、ベンダー側もお客様側も共通して持っていると共通理解が進み、良いプロジェクトになると思います。
—— 良いプロジェクトになるためのデータサイエンスチームの動きをもう少し具体的に教えてください。
中林:例えばSNS, Twitterなどのソーシャルデータとお客様企業内のデータをつなげるといったケースがあります。
金融、カード、ECのお客様と購買データやクレーム情報をつなげるなどです。ソーシャルデータもオープンなSNSから収集する場合やネットゲーム事業者のように 自分の土俵にいるユーザのデータを扱うケースなど様々です。
これらは、いわゆるテキストマイニングのスキルも重要であり、サイエンティストチームではIBMの東京基礎研究所にいる数理解析チームを使います。
その他にもソーシャルデータから商品開発のヒントを得るケースもあります。近年では「たべる ラー油」のように製品特性がとんがっていれば分かりやすいのですが、大ヒット商品ばかりを狙うのではなく、ロングテールのお腹から尻尾にかけてのポジショ ンで隠れたヒット商材を拾うといったトライするのです。
ビッグデータという意味ではマシンデータ(機械から出てくるログ)の分析、活用はまだまだこ れからの領域です。それぞれの機械からログは出し続けているが、垂れ流しの状態で、分析されていないのが現状です。故障の前兆を知るといったフレームワー クもまだ確立されていないのです。例えば、ネットワーク機器を大量に持っているお客様でいえば、携帯事業会社、ケーブルTV、データセンターなどです。
お客様にとっては稼働してからが本番です
—— マシンデータなどは、コマツなどのグローバル企業が利用している事例などを見ますね。もっと進んでいるのかと思っていましたが、サイエンティストチームの活躍の場は多そうです。
さて、冒頭のひとことに戻りますが「システムが稼働した後もデータ・インサイトは重要」という点についてお願いします。
中林:はい。理想的なプロジェクトの進め方をまとめながらお話します。
大抵は、お客様は漠然とした状況からスタートします。
その時期のミーティングでは、活動が具体化できていない、対象データが絞れないという状況です。そもそも実現できるのか不明であくまでもニーズが存在しているだけです。
そして、ミーティングの中で実現したいスコープ、ゴールを定めていくのですが、そこで、いきなり道具を使って構築しないで、トライアルから始めるのです。
お互いに学習しながら、要望にフィットしたものができてきたら、実際のプロジェクトで使ってみる。
ここからようやくインサイトを利用してこうすればいいのかな、という実験ができる。我々はPOC(Proof of Concept)と呼んでいます。ここからがインサイト・ミーティングの本番になるのです。
そのPOCで何を採用するかがデータサイエンスチームの腕の見せどころです。
IBMのテクノロジーでいうと、大量のソーシャルデータを扱うためのBigInsights(Hadoop)+テキスト解析エンジン、大量のデータをリアルタイムに処理・分析するためのストリーム・コンピューティング(Streams)、大量データを柔軟に高速に分析するPureData(Netezza)などがあります。
—— 仕掛け、インターフェースを構築して、カットオーバーして受け渡しで終わりという従来にありがちなモデルではなく、カットオーバーしてからが本番になる。そこでインサイト・ミーティングを続けていく価値があるということですね。
中林:はい。ベンダー側の視点ですが、モノ売りから入っても成果がでづらい時代になりました。
—— おっしゃるとおりですね、そのテーマはIT業界だけではないかと思います。
だからこそ、実際の現場でデータ・インサイトの使い方や使うタイミングなどを体系的にまとめて、皆様に紹介するのは価値がありそうです。今度、TiDのセミナーでテーマにしてみすので、是非ご協力ください。
中林:はい、喜んで。
—— それは心強いです。本日は長い時間ありがとうございました。
中林:ありがとうございました。
*編集後記*
実はもっと数理モデルの突っ込んだ話になるかと思っていましたが、データ・インサイト・ミーティングの存在とそれを活用したお客様との接点など、
営業やプロジェクトマネージャーにとっても有益なお話でした。
IBMのデータサイエンスの力に今後も期待しています。